

北京时间4月17日凌晨,OpenAI的多模态推理大模型o3与o4-mini重磅上线,这一大模型号称是OpenAI迄今最强、最智能的模型。
然而,研究机构很快发现,o3人工智能模型的开发方和第三方基准测试结果存在明显差异,这引发了人们对该公司透明度和模型测试实践的质疑。

OpenAI测试作弊了?
去年12月,OpenAI在预发布o3时,就强调了该模型在解决困难问题上的能力大幅提升。当时OpenAI声称,该模型可以回答FrontierMath(一组具有挑战性的数学问题)中超过25%的问题。这个分数远远超过了其竞争对手——排名第二的模型只能正确回答大约2%的FrontierMath问题。
OpenAI首席研究官Mark Chen当时在直播中表示:
“今天,所有大模型产品(能解决的FrontierMath问题的数量)的比例都不到2%…我们(在内部)看到,在积极的测试时间计算设置中,我们能够获得超过25%的解题率。”
但第三方测试证明,这个25%的数字很可能并不准确。
美东时间上周五(4月18日),开发“FrontierMath”的研究机构“Epoch AI”公布了“o3”的独立基准测试结果。Epoch发现,o3的得分约为10%,远低于OpenAI声称的最高得分25%。
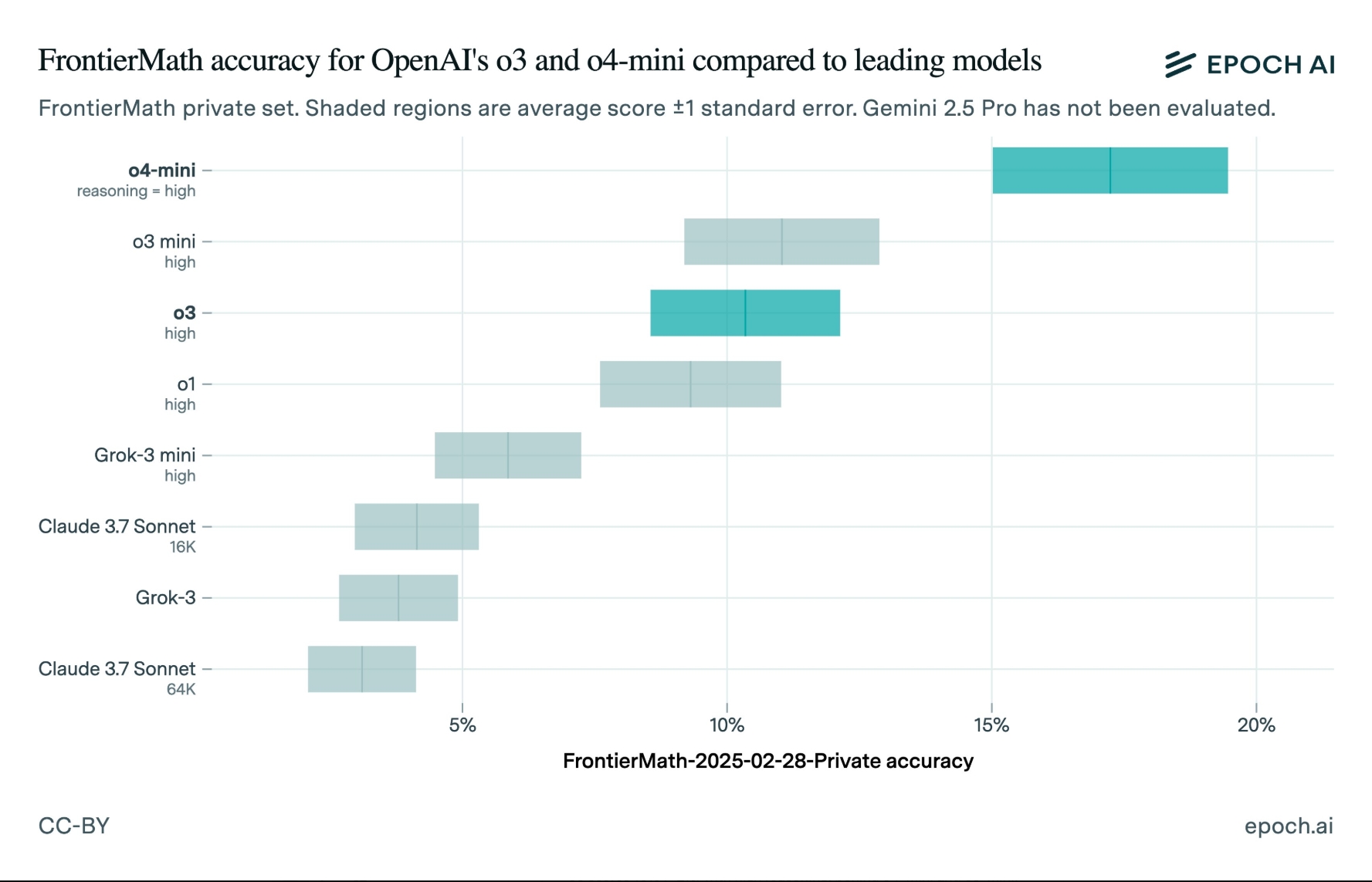
当然,这并不意味着OpenAI一定在撒谎。该公司去年12月发布的基准测试结果显示,其得分的下限与Epoch AI观察到的得分相当。Epoch AI还指出,他们的测试设置可能与OpenAI不同,即他们使用了FrontierMath的更新版本进行评估。
还没有评论,来说两句吧...